8.5 Proposed solution
In the previous section, we have described the data that we have available, and an annotation schema with which to organize and store the information contained within each image in our dataset. This schema is a modelization of the problem we want to solve: extracting a computational representation of the semantics represented by SignWriting images. As we saw in Section 8.3, we can train machine learning algorithms to learn the underlying patterns in annotated data, so that they are able to reproduce them in other, previously unseen, data samples. Therefore, we can use these algorithms, in particular neural networks, to learn and reproduce the modelization of our problem implicit in our corpus annotations, and solve our problem this way.
As a first approach and baseline for comparison, we use a state-of-the-art computer vision algorithm: YOLO. This is a deep learning detector and classifier neural network architecture, which can solve the full task with one single network, but has many limitations. Our proposed solution is a second approach which addresses some limitations of the first, combining additional networks into a branching pipeline which intelligently decides the paths to follow. This allows us to exploit the expert knowledge encoded into the corpus annotations, and solve a data problem in which a Big Data approach is not enough.
8.5.1 One-shot Approach
YOLO networks, as introduced in Section 8.3.2, seem like a perfect fit for our problem. They solve detection and classification in one step, so given a logogram, they should be able to locate the different graphemes depicted and assign a label to each of them. A problem might be that our graphemes are tagged with many different features, but we can create a different label for each feature combination (concatenating tag values) and give this resulting label to the network to learn. From this single label, the different features can then be extracted, and so the full task of SignWriting resolved. We use YOLO version 3, from Redmon y Farhadi (2018), as implemented in https://github.com/AlexeyAB/darknet.
We will examine the results later, in Section 8.6, but this one-shot solution will prove to be not enough for our problem. Essentially, there is too much complexity in our data for the single neural network to solve it successfully.
8.5.2 Expert Knowledge-based Pipeline Approach
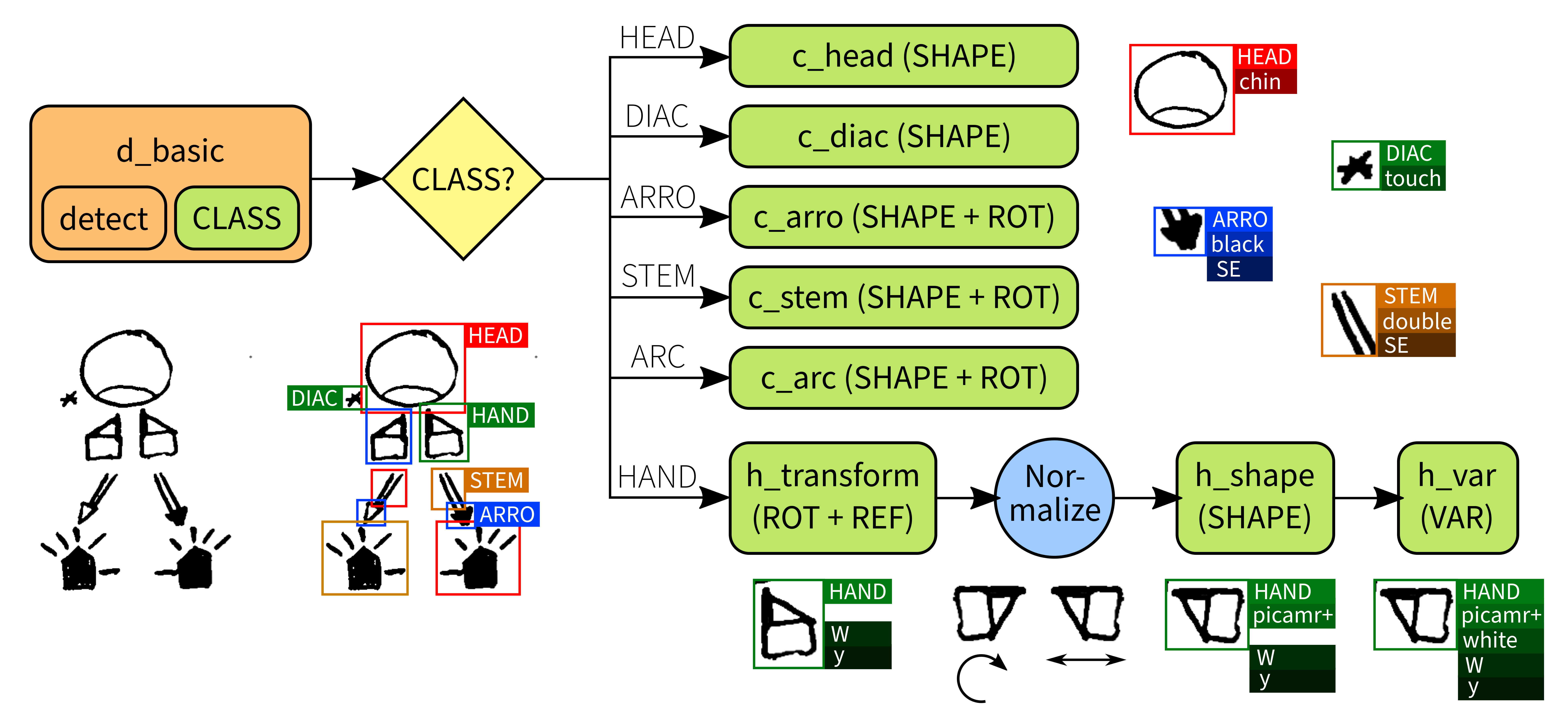
To make the detection problem more approachable, we have to reduce
the information that is passed to the neural network. Instead of
telling it that each possible different grapheme is an object to
locate, we can omit some of this information, and just have the
network learn to find a few rough groups of graphemes (the
CLASS tag from Section 8.4). This
way, the detector network learns to find objects abstracting away some
of their details, which makes it more able to generalize, and thus
increasing its ability to find graphemes which are not seen exactly so
in the training data.
Then, we can use a different procedure to complete the missing
features. Since detection has already been performed, we can extract
the region of the image where the detected grapheme is found, and
utilize only this sub-image. This lets us ignore all information
unrelated to the particular grapheme in question, and what we have
left is a new task of, given an image depicting just a grapheme, find
out the features it represents. Moreover, since we already have the
rough grouping given by the detection step (the CLASS
tag), we can use different processes for each of the grapheme
classes.
For most of them, it is enough to use a single neural network to learn all of the remaining features. We use AlexNet, as introduced in Section 8.3.2, and treat this problem as one of image classification. For each grapheme, a label is computed by concatenating its features, just like was done for the one-shot YOLO. The difference is that now we train different networks for each of the grapheme classes, reducing the number of labels they have to learn, and letting them concentrate in the specifics of each different grapheme instead of the commonalities to the whole group.
The case of hand graphemes is a little different. As we saw in Section 8.4, hand
graphemes have each four distinct features in addition to the
CLASS, that is the SHAPE (finger
configuration), the VAR (palm orientation) as well as the
graphical transformation (ROTation and
REFlection). There are more than 50 hand shapes in our
corpus, which multiplied by a possible 6 different variations, 8
rotations and 2 reflections (normal and mirrored) give a total of more
than 4000 possible combinations. This is too difficult for the network
to learn, more so given the scarcity of our data, so we further
subdivide the problem.
First, a classifier (again AlexNet) is used to detect the
transformation of the grapheme (rotation and reflection). Once the
transformation is detected, the grapheme is normalized to a standard
form (North rotation, no mirroring). A second AlexNet classifies this
normalized form, finding its SHAPE, and a third and last
network finds the VAR. This way, we encode our knowledge
of SignWriting into deterministic rules and steps of processing. The
neural networks are still in charge of detecting the visual patterns
that constitute the graphemes, a task better suited to deep learning,
but reconstructing the grapheme tags from the different visual
patterns is done in the glue between the networks. This means each
network only has a smaller task to learn, which it can tackle even
with the limited data available. The normalization of rotation and
reflection is again a deterministic rule, which transforms the data in
ways that we know make sense, freeing the networks from having to do
the work of generalizing such transformations.
The full pipeline for SignWriting can be seen in Figure 8.7, with an example logogram for reference.